























A.M. TURING AWARD LAUREATES BY...

Birth: 8 June, 1955.
Education: Bachelor’s degree in Physics (Queen’s College, Oxford, 1976).
Experience: Principal Engineer (Plessy, 1976-78), Programmer (D.G. Nash, 1978-80), Contractor (CERN, 1980), Technical manager (Image Computer Systems, 1981-1984), Technical staff (CERN, 1986-1994), Professor (MIT, 1994-Present). 3Com Founders Chair since 1999). Director & Founder of: The World Wide Web Consortium (1994-present) and World Wide Web Foundation (2008-present). Secondary appointments as Professor at Southampton University (2004-present); Professor at Oxford University in Computer Science (2016-Present).
Honors and Awards (selected): ACM Software System Award (1992); Distinguished Fellow of the British Computer Society (1995); Fellow of the Royal Society (2001), Fellow of the American Academy of Arts and Sciences (2001), Royal Society of Arts Albert Medal (2002), Japan Prize (2002), Computer History Museum Fellow (2003); Knight Commander of the Order of the British Empire (KBE); Order of Merit (2007); Draper Prize (2007); Fellow of the IEEE (2008); UNESCO Niels Bohr Gold Medal (2010), Queen Elizabeth II Prize for Engineering (2013); ACM A.M. Turing Award (2016). 19 honorary doctorates as of 2014.
Sir Tim Berners-Lee

United Kingdom – 2016
CITATION
For inventing the World Wide Web, the first web browser, and the fundamental protocols and algorithms allowing the Web to scale.
Tim Berners-Lee grew up in London. Both of his parents (Mary Lee Woods and Conway Berners-Lee) were mathematicians, who had worked on the Ferranti Mark 1, a pioneering effort to commercialize the early Manchester computer. He inherited their interests, playing with electronics as a boy, but choosing physics for his university studies. After earning a degree from Queen’s College, Oxford in 1976 he worked on programming problems at several companies, before joining the European physics lab CERN in 1984. His initial job was in the data acquisition and control group, working to capture and process experimental data.
Inventing the Web
CERN’s business was particle smashing, not computer science, but its computing needs were formidable and it employed a large technical staff. Its massive internal network was connected to the Internet. In March 1989 Berners-Lee began to circulate a document headed “Information Management: A Proposal,” which proposed an Internet-based hypertext publishing system. This, he argued, would help CERN manage the huge collections of documents, code, and reports produced by its thousands of workers, many of them temporary visitors.
Berners-Lee later said that he had been dreaming of a networked hypertext system since a short spell consulting at CERN in 1980. Ted Nelson, who coined the phrase “hypertext” back in the 1960s, had imagined an online platform to replace conventional publishers. Authors could create links between documents, and readers would follow them from one document to another. By the late-1980s hypertext was flourishing as a research area, but in practice was used only in closed systems, such as the Microsoft Windows help system and the Macintosh Hypercard electronic document platform.
Mike Sendall, Berners-Lee’s manager, wrote “vague but exciting” on his copy of the proposal. In May 1990, he authorized Berners-Lee to spend some time on his idea, justifying this as a test of the widely hyped NeXT workstation. This was a high-end personal computer with a novel Unix-based operating system that optimized the rapid implementation of graphical applications. Berners-Lee spent the first few months working out specifications attempting to interest existing hypertext software companies in his ideas. By October 1990, he had begun to code prototype Web browser and server software, finishing in December. On 6, August, 1991, after tests and further development inside CERN, he used the Internet to announce the new “World Wide Web” and to distribute the new software.
Elements of the Web
The World Wide Web was ambitious in some ways, as its name reflects, but cautious in others. Berners-Lee’s initial support from CERN did not consist of much more than a temporary release from his other duties. So he leveraged existing technologies and standards everywhere in the design of the WWW. He remembers CERN as “chronically short of manpower for the huge challenges it had taken on.” There was no team of staff coders standing by to implement any grand plans he might come up with.
The Web, like most of the Internet during this era, was intimately tied in with the Unix operating system (for which Dennis M. Ritchie and Ken Thompson won the 1983 Turing Award). For example, the first Web server (and most since) have run as background processes on Unix-derived operating systems. URLs use Unix conventions to specify file paths within a website. To develop his prototype software, Berners-Lee used the NeXT workstation. More fundamentally, Berners-Lee’s whole approach reflected the distinctive Unix philosophy of building new system capabilities by recombining existing tools.
The Web also followed the Internet philosophy of achieving compatibility through communications protocols rather than standard code, hardware, or operating systems. His specifications for the new system led to three new Internet standards.
Web pages displayed text. HTML (Hyper Text Markup Language) specified the way text for a Web page should be tagged, for example as a hyperlink, ordinary paragraph, or level 2 heading. It was an application of the existing SGML (Standard Generalized Markup Language) markup language definition standard.
HTTP (Hyper Text Transfer Protocol) specified the interactions through which Web browsers could request and receive HTML pages from Web servers. HTML was, in computer science terms, stateless – users did not log into websites and each request for a Web page or other file was treated separately. This made it a file transfer protocol, which was easy to design and implement because existing Internet standards and software, most importantly TCP/IP (for which Vinton Cerf and Robert E. Kahn won the 2004 Turing award), provided the infrastructure needed to pipe data across the network from one program to another. Berners-Lee later called this use of Internet protocols “politically incorrect” as European officials at the time were supporting a transition to the rival ISO network protocols. A few years later it was the success of the Web that put the final nail in their coffin.
Consider a Web address like http://amturing.acm.org/award_winners/berners-lee_8087960.cfm. This is a URL or Uniform Resource Locator (Berners-Lee originally called this a Universal Resource Identifier). The “amturing.acm.org” part identified the computer where the resource was found. This was nothing new – Internet sites had been using this Domain Name System since the mid-1980s. The novelty was the “http://” which told Web browsers, and users, to expect a Web server. Information after the first single “/” identified which page on the host computer was being requested. Berners-Lee also specified URL formats for existing Internet resources, including file servers, gopher servers (an earlier kind of Internet hypertext system), and telnet hosts for terminal connections. In 1994, Berners-Lee wrote that “The fact that it is easy to address an object anywhere in the Internet is essential for the system to scale, and for the information space to be independent of the network and server topology.”
The URL was the simplest of the three inventions, but was crucial to the early spread of the Web because it solved the “chicken and egg” problem facing any new communications system. Why set up a Web page when almost nobody has a Web browser? Why run a Web browser when almost nobody has set up a Web server to visit? The URL system made Web browsers a convenient way to access existing resources, cataloged on Web pages. In 1992, the Whole Internet Catalog and User’s Guide stated that “the World Wide Web hasn’t really been exploited yet… Hypertext is used primarily as a way of organizing resources that already exist.”
The Web Takes Off
CERN found some resources to support the further development of the Web – about 20 person years of work in total, mostly from interns. More importantly, it made it clear that others were free to use the new standards and prototype code to develop new and better software. Robert Cailliau, of the Office Computing Systems group, played an important role as a champion of the project within CERN. In 1991 CERN produced a simple text-based browser that could easily be accessed over the Internet and a Macintosh browser, essential to the initial spread of the Web as NeXT workstations remained very rare.
Over the next few years others implemented faster and more robust browsers with new features such as graphics in pages, browser history, and forward and back buttons. Mosaic, released in 1993 by the National Center for Supercomputer Applications of the University of Illinois, brought the Web to millions of users. In April, 1994 CERN, which was still trying to maintain a comprehensive list of Web servers, cataloged 829 in its “Geographical Registry.”
Berners-Lee later attributed his success largely to “being in the right place at the right time.” He succeeded where larger and better funded teams had failed, setting the foundation for a global hypertext system that quickly became a universal infrastructure for online communication and the foundation for many new industries. Yet the ACM’s 1991 Hypertext conference had rejected Berners-Lee’s paper describing the World Wide Web. From a research viewpoint, the Web seemed to sidestep many thorny research problems related to capabilities that Ted Nelson thought essential for a public hypertext publication system. If a Web page was moved, then links pointing to it stopped working. If the target page was changed, then it might no longer hold the content the link promised. Links went only one way – one couldn’t see which other pages linked to a document. There was no central, searchable index of websites and their content. Neither did the Web itself provide any way for publishers to get paid when people read their work.
Berners-Lee had only a few months at his disposal, which may have been a hidden blessing: Nelson worked for decades without coming close to finishing his system. Rather than attack intractable problems, Berners-Lee used proven technologies as the building blocks of a system intended to be powerful and immediately useful rather than perfect.
The Web’s reliance on existing technologies was appealing to early users and eased deployment – setting up a Web server on a computer already connected to the Internet just involved downloading and installing a small program. This technological minimalism made the Web easy to scale, with no indexing system or central database to overload. After the Web took off, whole new industries emerged to fill in some of the missing capabilities needed for large scale and commercial use, eventually leading, for example, to the rise of Google as the dominant provider of Internet search.
One crucial feature that Berners-Lee built into his prototype Web software was left out of its successors. His browser allowed users to edit pages, and save the changes back on the server. His 1994 article in Communications of the ACM noted that “The Web does not yet meet its design goal of being a pool of knowledge that is as easy to update as to read.” Editing capabilities were eventually added in other ways – first through separate HTML editing software, and later with the widespread adoption of content management systems where the software used to edit Web pages is itself accessed through a Web browser.
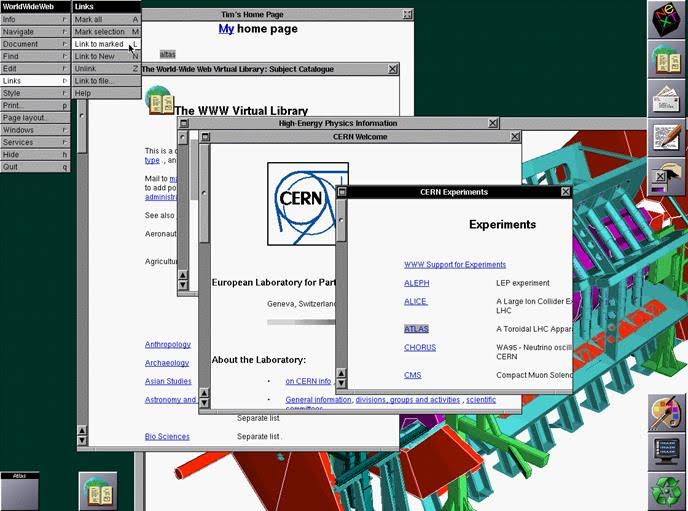
A screenshot of Berners-Lee’s Web browser software running on his NeXT computer. Note the Edit menu to allow changes, and the Style menu which put decisions over fonts and other display details in the hands of the reader rather than Webpage creators. Since 2014 this computer has been exhibited at the Science Museum in London.
Berners-Lee feels that his original design decisions have held up well, with one exception: the “//” in URLs which make addresses longer and harder to type without adding any additional information. “I have to say that now I regret that the syntax is so clumsy” he wrote in 2009.[1]
Standardizing the Web
Mosaic’s successor, the commercial browser Netscape, was used by hundreds of millions and kickstarted the “.com” frenzy for new Internet stocks. By 2000 there were an estimated 17 million websites online, used for commercial transactions such as online shopping and banking as well as document display. In the process, HTML was quickly given many clunky and incompatible extensions so that Web pages could be coded for things like font styles and page layout rather than its original focus on document structure.
In 1994 Berners-Lee left CERN for a faculty job at MIT. This let him establish the World Wide Web Consortium (W3C), to standardize HTML and other, newer, elements of the Web. Berners-Lee had been frustrated in 1992 in an initial attempt to work with the Internet Engineering Task Force, the group that developed and standardized other Internet protocols. The consortium followed a different model, using corporate memberships to support the work of paid staff members. With its guidance the Web has remained open during its growth, so that users can choose their preferred Web browser while still accessing the full range of functionality found on modern websites. It also played a crucial role in adoption of the XML data description language. As of 2017, his primary appointment remains at MIT where he holds the Founders Chair in the MIT Computer Science and Artificial Intelligence Laboratory and continues to direct W3C.
The Semantic Web
Since the late 1990s Berners-Lee’s primary focus has been on trying to get Web publishers and technology companies to add a set of capabilities he called the “Semantic Web.” Berners-Lee defined his idea as follows: “The Semantic Web is an extension of the current Web in which information is given well-defined meaning, better enabling computers and people to work in cooperation."
Document metadata was largely left off the original Web, in contrast to traditional online publishing systems, which made it hard for search engines to determine basic information such as the date on which an article was written or the person who wrote it. The Semantic Web initiative covered a hierarchy of technologies and standards that would let the creators of Web pages tag them to make their conceptual structure explicit, not just for information retrieval but also for machine reasoning.
Legacy and Recognition
The success of the Web drove a massive expansion in Internet access and infrastructure – indeed most Internet users of the late-1990s experienced the Internet primarily through the Web and did not clearly separate the two. Berners-Lee has been widely honored for this work, winning a remarkable array of international prizes. Sir Tim, as he been known since the Queen knighted him in 2004, has been recognized as one of the public faces of British science and technology. In 2012 he appeared with a NeXT computer during the elaborate opening ceremony of the London Olympic Games.
He has been increasingly willing to use this public influence to impact the ways in which governments and companies are shaping the Web. In 2009 he set up the World Wide Web Foundation, which lobbies for “digital equality” and produces rankings of Web freedom around the world. More recently, Berners-Lee has championed protection for personal data, criticized the increasing dominance of proprietary social media platforms, and bemoaned the prevalence of fake news online.
Author: Thomas Haigh


 THE A.M. TURING AWARD
THE A.M. TURING AWARD